
BRIN vs B-Tree Index in PostgreSQL: When to Use Which

Indexes are essential for optimizing query performance in PostgreSQL. Two common index types are BRIN (Block Range INdex) and B-Tree (Balanced Tree). Each has its strengths and weaknesses, making them suitable for different scenarios.
In this post, we'll compare BRIN and B-Tree indexes, explain when to use each, and provide real-world examples to illustrate their differences.
1. Understanding BRIN and B-Tree Indexes
What is a B-Tree Index?
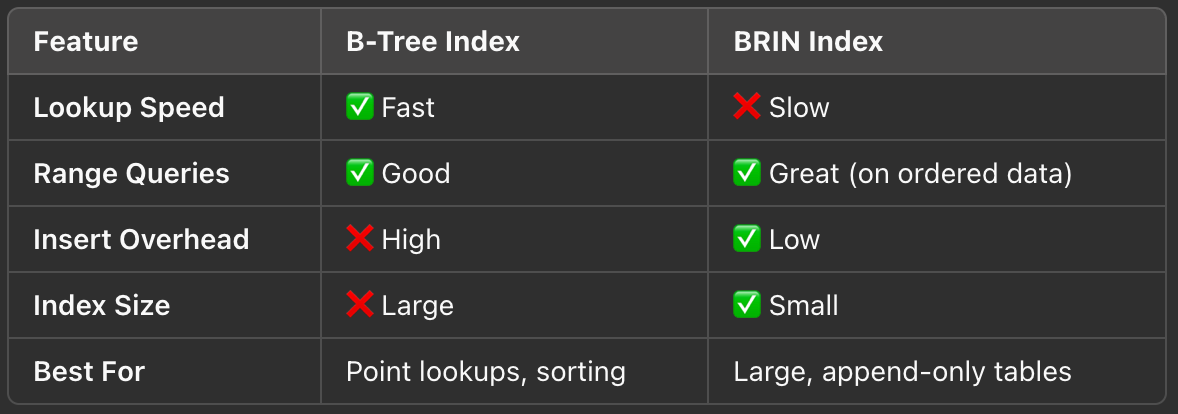
B-Tree (Balanced Tree) is the default and most commonly used indexing method in PostgreSQL. It works by organizing data in a hierarchical tree structure, allowing fast searches, insertions, and deletions.
🔹 Best for: Lookups, sorting, and filtering across a broad range of queries.
What is a BRIN Index?
BRIN (Block Range INdex) is a lightweight index type designed for very large tables. Instead of indexing every row, BRIN stores summary metadata (min/max values) for blocks of rows, making it much smaller in size.
🔹 Best for: Large, naturally ordered datasets where queries target specific ranges.
2. Comparing BRIN vs. B-Tree with Examples
Example Use Case: Sensor Data
Consider a table storing temperature sensor readings:
CREATE TABLE sensor_readings (
id SERIAL PRIMARY KEY,
sensor_id INT NOT NULL,
temperature FLOAT NOT NULL,
recorded_at TIMESTAMP DEFAULT NOW()
);
Let's say we insert 100 million rows into this table, where recorded_at is naturally increasing.
Using a B-Tree Index
CREATE INDEX btree_sensor_time ON sensor_readings (recorded_at);
🔹 Pros:
Efficient for point lookups (e.g., searching for a specific timestamp).
Fast for sorting and range queries when data isn't sequentially ordered.
Works well even if data is frequently updated.
🔹 Cons:
Large index size because it indexes every row.
More disk space and maintenance overhead.
Using a BRIN Index
CREATE INDEX brin_sensor_time ON sensor_readings USING BRIN (recorded_at);
🔹 Pros:
Very small index size (only stores metadata per block, not every row).
Fast for range queries on naturally ordered data.
Ideal for append-only workloads (e.g., logs, time-series data).
🔹 Cons:
Slow for point lookups (must scan blocks to find exact matches).
Less effective if data is frequently updated or not naturally ordered.
3. Performance Comparison
Scenario 1: Finding a Specific Timestamp
Query: Find a specific temperature reading from a given timestamp.
SELECT * FROM sensor_readings WHERE recorded_at = '2025-01-01 12:00:00';
B-Tree: Uses binary search for fast lookup (O(log N)). ✅ Fast
BRIN: Scans multiple blocks to locate the value. ❌ Slow
🏆 Winner: B-Tree
Scenario 2: Finding All Readings in the Last 24 Hours
Query: Get readings from the last day.
SELECT * FROM sensor_readings WHERE recorded_at >= NOW() - INTERVAL '1 day';
B-Tree: Performs well but must scan all indexed rows.
BRIN: Quickly narrows down to relevant blocks. ✅ Efficient
🏆 Winner: BRIN (especially on massive datasets)
Scenario 3: Inserting Millions of Rows
B-Tree: Large index size causes higher insertion overhead.
BRIN: Minimal overhead, as it only updates block summaries.
🏆 Winner: BRIN (for bulk inserts in append-only tables)
4. When to Use B-Tree vs. BRIN?
✅ Use B-Tree When:
You need fast lookups for specific values.
Your dataset is not naturally ordered.
Data is frequently updated or deleted.
Queries involve sorting, joins, or complex filtering.
✅ Use BRIN When:
Your table is massive (millions/billions of rows).
Data is naturally ordered (timestamps, auto-incremented IDs).
Queries mostly involve range scans.
The dataset is append-only (e.g., logs, sensor data).
5. Conclusion: Choosing the Right Index
For most cases, B-Tree is the default choice, but if you're dealing with huge tables with naturally ordered data, BRIN can provide significant performance and storage benefits.
Would you like help implementing the best index strategy for your PostgreSQL workload? Let’s discuss in the comments! 🚀