
Building and running a distributed data variance tool successfully in production at Wayfair
Fixing data sync issues during data movement in a large scale distributed system.


Authors: Diljit Ramachandran, Gitesh Jain, Abhinav Patni
Imagine you have two datasets—maybe they’re stored in different databases or different data stores. Now, how do you ensure that these two datasets are perfectly in sync, especially when the definition of "in sync" can vary depending on the business context? If they’re not in sync, how do you find out what’s causing the discrepancy?
Sounds intriguing, doesn’t it?
This was exactly the challenge we faced at Wayfair when we embarked on a complex journey: transitioning from a legacy application to a modern, decoupled micro-service architecture on Google Cloud Platform (GCP). It wasn’t just about moving data from one place to another; it was about ensuring that data integrity was maintained every step of the way, even as we transformed the very foundation of our system.
During this migration, we encountered a critical issue: data synchronisation. How could we guarantee that the data being moved from our old, monolithic system to our new, scalable micro-services would remain consistent and accurate? The stakes were high—any mismatch could lead to significant operational disruptions.
To tackle this challenge, we built a powerful tool that didn’t just detect discrepancies but also offered the ability to automatically correct them based on our specific business logic. This tool became our secret weapon in ensuring that our data remained reliable throughout the transition, successfully mitigating the risks of data synchronisation issues.
Curious about how we did it? Stay tuned as we dive into the details of this tool and how it became the linchpin of our data migration strategy.

In today's data-driven world, ensuring the accuracy and consistency of data as it flows through various systems is paramount, especially in mission-critical environments like supply chain management. At our company, we faced a challenge with the way data was transferred and processed between systems.
Our data pipeline, which operates similarly to a Change Data Capture (CDC) mechanism but in batch mode, is responsible for moving events from a source change detection system to a Kafka topic. From there, our decoupled microservice application listens to these events, transforms them, and persists the results in our database.
However, a few issues surfaced. First, we couldn’t always rely on the intermediary systems between the source and destination to be completely error-free. Second, as users began to interact with our new application, they required consistent and correct results, even when dealing with older data passed through the pipeline. In a mission-critical system, the margin for error is extremely slim, and ensuring the integrity of data is non-negotiable.
Given these challenges, we decided to develop a robust solution to detect and correct any discrepancies that might occur between the source and destination datasets. Enter SyncGuard—our in-house data variance tool designed to identify and rectify variances in real-time, ensuring that data remains consistent and reliable across the board.
SyncGuard is built with simplicity in mind, making it easy for engineers to onboard and write custom variance detection tools tailored to different business contexts. Its architecture is designed for quick deployment and integration, allowing teams to maintain data integrity with minimal effort.
In this article, we’ll dive into the architecture of SyncGuard, exploring how it works, the problems it solves, and how it can be adapted to various business needs.

A better workflow with the relevant technologies show below:
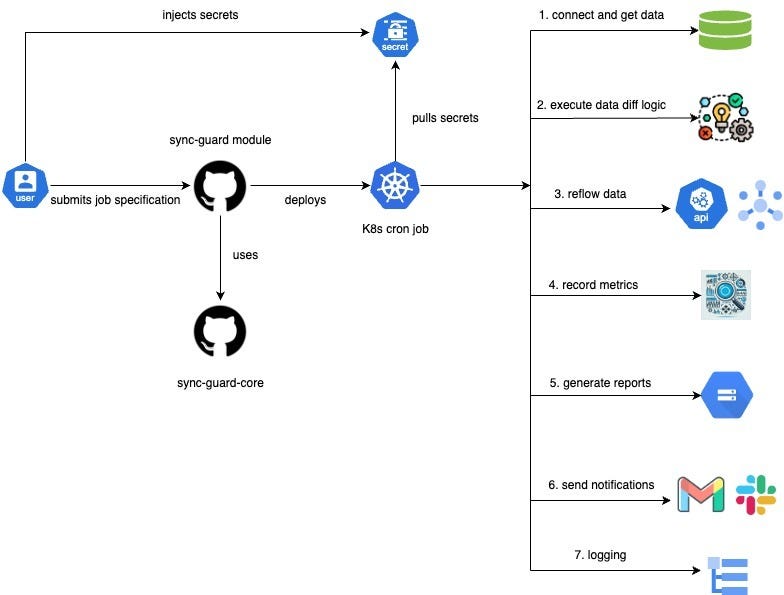
The Challenge: Data Consistency in Complex Systems
As data flows through various systems—from source change detection to Kafka topics and ultimately to databases—ensuring its accuracy and consistency becomes increasingly complex. Intermediary systems can introduce bugs, and relying solely on their correctness isn’t enough, especially when delivering consistent results to users is paramount. This is where SyncGuard steps in, providing a safety net that detects and corrects discrepancies before they impact operations.
How SyncGuard Works: The Power of YAML Configuration
The true strength of SyncGuard lies in its YAML-based configuration, which offers flexibility and ease of use. The YAML file is structured into several key sections, each playing a crucial role in the tool's functionality:
DataSource Information: This section defines the source datastore, query configurations, batch sizes, database credentials, and the specific query to be executed. By centralizing these settings, SyncGuard ensures that data retrieval and processing are tailored to the exact needs of your business context.
Notification Information: Timely alerts are essential when variances are detected. In this section, users can configure how and where notifications are sent—be it through email, Slack channels, or other communication platforms—ensuring that teams are immediately informed of any issues.
Observability Information: SyncGuard doesn’t just detect problems; it also tracks its performance. This section allows users to push metrics to monitoring systems, providing visibility into the status of variance detection processes. Teams can then set up alerts, like PagerDuty, to be notified if something goes wrong.
Reconciliation: When a variance is detected, SyncGuard steps in to correct it. This section allows users to specify how data should be reflowed from the source to the destination. With support for various adapters and handlers—such as Kafka and HTTP REST APIs—SyncGuard ensures that data is accurately synced.
Reporting: Beyond detection and correction, SyncGuard also logs its activities. This section enables the storage of job-specific run
name: "nodes-ui-schedules-data-diff-prod"
description: "Syncguard job to identify and fix Nodes Ui Schedules data discrepancies between Legacy NodesUi and Facility Core.\n
You can find more details about the job implementation here -
Documentation on how to handle discrepancies available here -
version: 2
dataSources:
- name: "legacyNodesUiDB"
id: 1
url: "jdbc:sqlserver://hosturl;MultiSubnetFailover=True;applicationName=syncguard"
sourceType: "SQL_SERVER"
queryConfig:
mode: PARALLEL
batchSize: 100000
threadPoolSize: 5
retries: 2
waitFor: 1800000
credential:
userId: "syncguard-service-account"
password: "${syncguard-service-account}"
queries:
- name: "nodesUiSchedulesQuery"
offsetColumn: "NodeID, NodeScheduleNomenclatureID, NodeScheduleType, NodeScheduleStartDateTime, NodeScheduleEndDateTime"
batchingStrategy: LIMIT_OFFSET
totalRecordSize: 1000000
timeout: 600000
query: |
some sql query here"
- name: "facility-core"
id: 1
url: "jdbc:postgresql://${SYNCGUARD_CLOUDSQL_SERVICE_HOST}/facility-core_db"
sourceType: "POSTGRES_SQL"
queryConfig:
mode: PARALLEL
batchSize: 100000
threadPoolSize: 5
retries: 2
waitFor: 1800000
credential:
userId: "facility-core"
password: "${psql_facility-core_db}"
queries:
- name: "fcNodesUiSchedulesQuery"
query: |
some businss query here
"
batchingStrategy: LIMIT_OFFSET
totalRecordSize: 1000000
timeout: 600000
- name: "fcScheduleTypeIdsQuery"
offsetColumn: "ScheduleTypeId"
batchingStrategy: LIMIT_OFFSET
totalRecordSize: 6000
timeout: 600000
query: |
"some business query here"
- name: "fcNodeMappingQuery"
offsetColumn: "id"
batchingStrategy: LIMIT_OFFSET
totalRecordSize: 10000
timeout: 600000
query: "some business query here"
serviceName: "party-core"
schedule: "* * * 6-9 * *"
observability:
type: "DATADOG"
metricName: "nodes.ui.schedules.data.discrepancy.prod"
monitorName: "PROD - NodesUi - FC Schedules data discrepancy alert"
query: "sum(last_1h):sum:nodes.ui.schedules.data.sync.discrepancy.prod{*} > 0"
alertMessage: "PROD NodesUI and FC schedules Table data not in sync"
priority: 5
tags:
- name: "service"
value: "nodes-ui-schedules-diff"
- name: "team"
value: "facility-core"
- name: "env"
value: "prod"
notification:
- name: "nodes-ui-schedules-data-mismatch-email-notify-prod"
teamName: "Facility-Core"
type: "EMAIL"
mailTo:
- "team1@wayfair.com"
- "team2@wayfair.com"
mailFrom: "noreply@wayfair.com"
- name: "nodes-ui-schedules-data-mismatch-slack-notify-prod"
teamName: "Facility-Core"
type: "SLACK"
webhook: "slackwebhookhere"
reporting:
name: "nodes-ui-schedules-data-mismatch-report-prod"
type: "EMAIL"
format: "CSV"
reflowConfig:
destination:
- name: "CreateMissingSchedules"
reflowType: "REST_API"
endpointUrl: "resturl"
httpMethod: "POST"
- name: "DeleteExtraSchedules"
reflowType: "REST_API"
endpointUrl: "restendpointurl"
httpMethod: "DELETE"
featureHub:
type: "UNLEASH"
name: "facility-core-unleash"
appName: "togglename"
userId: "toggleuser-id"
secret: "secret"
url: "feature toggle url"Let’s have a closer look what the YAML file is all about:
This YAML configuration represents a SyncGuard job setup designed to identify and fix data discrepancies between the Legacy NodesUi and Facility Core databases. Below is a breakdown of the key sections:
Job Overview
Name: nodes-ui-schedules-data-diff-prod
Description: A SyncGuard job aimed at detecting and resolving discrepancies in NodesUi Schedules data between Legacy NodesUi and Facility Core systems.
Version: 2
Data Sources
The job works with two data sources, legacyNodesUiDB and facility-core, both using different database types.
legacyNodesUiDB (SQL Server):
URL: Points to the SQL Server database with relevant connection parameters.
Query Config: Executes queries in parallel with a batch size of 100,000 records.
Queries: The key query here is
nodesUiSchedulesQuery, which pulls schedule data for comparison.
facility-core (PostgreSQL):
URL: Connects to a PostgreSQL database, with details provided via environment variables.
Query Config: Similar parallel processing configuration.
Queries: Includes multiple queries such as
fcNodesUiSchedulesQuery,fcScheduleTypeIdsQuery, andfcNodeMappingQuery, each handling specific data extraction tasks.
Service Configuration
Service Name:
party-coreSchedule: Runs periodically as defined by the cron schedule
"* * * 6-9 * *".
Observability
Type:
DATADOGMetric Name: Monitors discrepancies via the metric
nodes.ui.schedules.data.discrepancy.prod.Alerting: Sets up an alert with a custom message and defined tags for monitoring.
Notification
The system is configured to notify teams via both email and Slack when discrepancies are detected:
Email: Sent to relevant teams.
Slack: Configured via a webhook to notify the
Facility-Coreteam.
Reporting
Type:
EMAILFormat: Reports generated in CSV format.
Reflow Configuration
Defines actions to take if discrepancies are found:
CreateMissingSchedules: A POST request to create missing schedules.
DeleteExtraSchedules: A DELETE request to remove any extraneous schedules.
Feature Hub Management
Type:
UNLEASHToggle: Feature toggling is handled through the
facility-core-unleashapplication, allowing dynamic adjustments to job configurations.
What happens when the job is executed?
The job is executed a cron job on the k8s cluster. Each job is packaged as a docker image which contains both the libraries and job code. Each job runs in islotion to ensure one job requirements do not affect the other. An example of which shown below.
fc_contacts_data_diff: resources: limits: cpu: 500m memory: 6Gi requests: cpu: 400m memory: 2Gi schedule: "0 */4 * * *" # run every hour successfulJobsHistoryLimit: 30 failedJobsHistoryLimit: 10 activeDeadlineSeconds: 1800 # command is mandatory even if entrypoint is defined in docker. command: - java - -cp - /app/build/app.jar - com.wayfair.syncguard.nodesui.contacts.NodesUIContactsProdApplicationThe SyncGuard framework parses the spec file, looks at the queries that needs to run and injects them to a java code exposed by the engineer who is responsible to write the sync job, An example code.
imports here @SpecFile("sync-guard-specification/prod/nodesUiContactsProd.yaml") @Component @Slf4j @Lazy public class NodesUIContactsProd extends AbstractBaseRunnerV2 { @Override public StageResult runWithBatch(Map<String, Optional<ResultIterator>> resultMap) { Map<String, Set<Contact>> fcContactsMap = resultMap .get("fcContactQuery") .map(FacilityContactsMapper::mapFromFcDBQueryResult) .orElseGet(HashMap::new); Map<Integer, Set<String>> nodeIdToFacilityIdMap = resultMap .get("legacyToFcNodeMappingQuery") .map(FacilityCapabilitiesMapper::mapNodeIdToFacilityId) .orElseGet(HashMap::new); Map<String, Contact> legacyContactMap = resultMap .get("nodeContactQuery") .map(FacilityContactsMapper::mapFromLegacyQueryResult) .orElseGet(HashMap::new); Map<String, List<Object>> metadata = ContactsDataDiffService.getDataDiff(legacyContactMap, fcContactsMap, nodeIdToFacilityIdMap); log.info( "data diff for reconciliation size : {} ", metadata.get(ContactsDataDiffService.DATA_MISSING_COUNT_KEY).size() + metadata.get(ContactsDataDiffService.DATA_MISMATCH_COUNT_KEY).size() + metadata.get(EXTRA_CONTACTS_IN_FC).size()); return RunStageResult.builder() .dataDiff(metadata) .success(ContactsDataDiffService.isSuccess(metadata)) .build(); } }The framework runs the code and expects a StageResult from each section which then utilises the information to send out alerts, monitoring and reports on the data sync job. We could also push custom data to the StageResult which we then utilise in our reconciliation flow to the fix data gap.
How the reconciliation works?
Ater identifying a data sync issue, SyncGuard offers two options for reconciling the data to resolve the inconsistency based on the logical definition. These options are specified in the reflowConfiguration section of the YAML file. Currently, SyncGuard supports both asynchronous and synchronous methods for data reconciliation:
Asynchronous Reconciliation:
Example: Kafka reconciliation adapters.
Description: In this method, the data is reflowed asynchronously using message queues like Kafka. This approach allows for more flexibility and can handle high volumes of data without impacting real-time processing.
Synchronous Reconciliation:
Examples: HTTP REST Endpoints, SOAP, GraphQL, etc.
Description: In this method, the data is reflowed synchronously via APIs, ensuring immediate correction and consistency. This method is typically used when the reconciliation process requires an immediate and direct update to the target system.
Following is a sample reporting email sent on slack for our teams to know about the job status, how may data points were not in sync, status of reconciliation and documentation for engineers to debug and identify issues.

What we have achieved so far?
ensured data across 3 major databases spanning across millions of rows are in sync through effective monitoring, alerts and reconciliation to help business move fast in the decoupling journey.
6 SyncGuard jobs to identify and fix critical business flows successfully running in production since past 3 months.
Emails, Slack and Pager Duty notifications to help teams to recognise, identify and fix issues proactively.
Building SyncGuard was not just fun but also a quick way on how to effectively design simple systems that fix data discrepancies that occur typically in a modern data flow environment. We have deliberately kept it simple inorder for engineers to quickly adopt and write sync jobs without having to worry about database connections, custom checks, etc.
If you have found it an interesting, please leave a comment below.
For more interesting engineering articles, subscribe me for more:
 | A guest post by
|