
Using Merkle Trees to Detect Data Variance Between Two Data Stores

In distributed systems, ensuring data consistency across multiple data stores is crucial. However, comparing large datasets across distributed nodes can be challenging and resource-intensive. One elegant solution to this problem is using Merkle trees—a data structure that allows efficient and reliable verification of the consistency between two datasets.
What is a Merkle Tree?
A Merkle tree, also known as a hash tree, is a binary tree where each leaf node represents the hash of a block of data, and each non-leaf node represents the hash of its child nodes. This structure enables efficient and secure verification of data integrity across distributed systems. If two Merkle trees have the same root hash, the data they represent is identical; if the root hashes differ, you can identify the exact point of variance by traversing the tree.
How Merkle Trees Work
Leaf Nodes: At the base of the tree, each leaf node contains the hash of a data block. For example, if you have four data blocks
D1,D2,D3,D4, the leaf nodes will be
H1=Hash(D1)
H2=Hash(D2)
H3=Hash(D3)
H4=Hash(D4)Non-Leaf Nodes: Each parent node contains the hash of its two children. So,
P1=Hash(H1+H2)
P2=Hash(H3+H4)Root Node: The root node contains the hash of the top two parent nodes.
R=Hash(P1+P2)
Here’s a visual representation of a Merkle tree:
R
/ \
P1 P2
/ \ / \
H1 H2 H3 H4
/ \ / \/ \ / \
D1 D2 D3 D4 D5 D6
Catching Data Variance Using Merkle Trees
To catch data variance between two data stores:
Create Merkle Trees: Each data store generates a Merkle tree representing its dataset.
Compare Root Hashes: Compare the root hashes of the two Merkle trees. If they match, the datasets are identical.
Traverse to Identify Variance: If the root hashes differ, traverse down the tree to identify the first point of divergence. Continue this process until you find the specific data block(s) that differ.
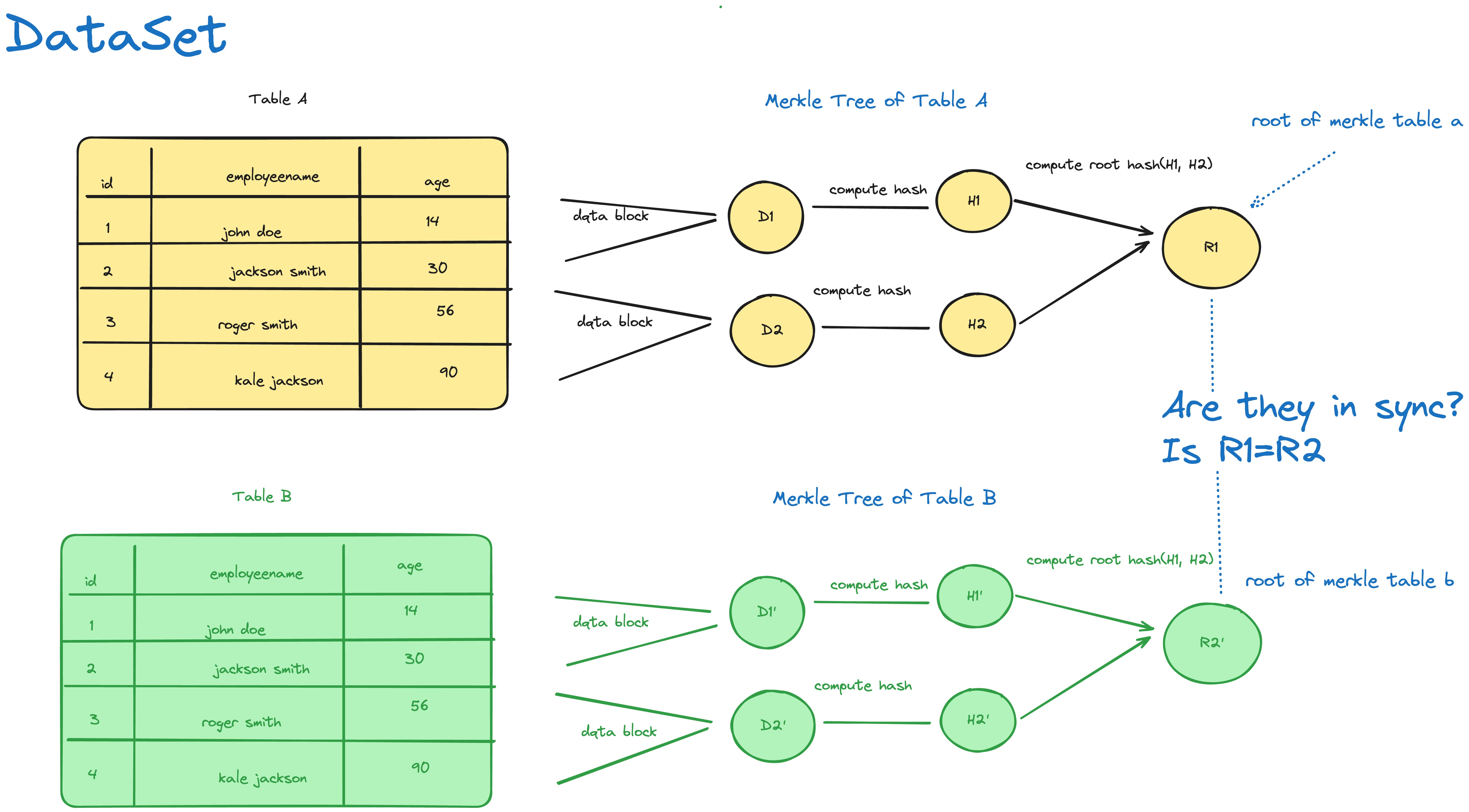
Example: Detecting Variance Between Two Data Stores
Imagine two distributed databases, A and B, each holding a large dataset. To verify that the datasets are identical, follow these steps:
Step 1: Generate Hashes
Each database generates hash values for every data block. For example:Database A: H1A, H2A H3A, H4A
Database B: H1B, H2B, H3B, H4B
Step 2: Construct Merkle Trees
Both databases create Merkle trees and compute the root hashes RA and RBStep 3: Compare Root Hashes
If RA≠RB, there is a variance. Traverse the trees to find the point of divergence. Suppose H1A=H1B and H2A≠H2B, the discrepancy lies in the data blocks contributing to H2.Step 4: Resolve the Variance
Once the divergent block is identified, the databases can synchronise that specific block, minimising data transfer.
Time and Space Complexity
Time Complexity
Tree Construction: The time complexity to build a Merkle tree is O(nlogn) where n is the number of data blocks. This is because computing each hash takes O(logn), and there are O(n)blocks.
Tree Comparison: Comparing two Merkle trees typically has a time complexity of O(logn), as you start from the root and only need to traverse the paths of differing nodes.
Space Complexity
Storage: The space complexity is O(n) for storing the hash values. Each non-leaf node in the tree needs to store a hash of its child nodes.
Communication: The amount of data transferred during comparison is significantly reduced, as only the differing branches of the tree need to be transmitted, leading to O(logn)O(\log n)O(logn) space complexity in the worst case.
Benefits in Distributed Systems
Efficiency: Merkle trees allow you to identify variances without comparing each data block directly, which is particularly useful in distributed environments with large datasets.
Scalability: As datasets grow, Merkle trees handle the increased size with logarithmic efficiency, making them scalable.
Data Integrity: By using cryptographic hash functions, Merkle trees ensure that even small changes in data are detectable, maintaining data integrity.
Quick Takeaway
Merkle trees offer an efficient and scalable method for detecting data variance between distributed data stores. By leveraging their hierarchical structure, you can quickly identify inconsistencies with minimal data transfer, making them ideal for use in distributed systems where data integrity and consistency are paramount.
Can we compute this in a high load environment?
Handling a high write scenario in a distributed system, where frequent inserts and updates occur, presents a unique challenge when using Merkle trees to detect data variance. In such scenarios, recalculating hashes for the entire dataset after each write operation would be inefficient and resource-intensive. Instead, a more strategic approach is needed to maintain and update the Merkle tree efficiently. Here’s how you can manage this:
Incremental Hash Updates
To handle frequent inserts and updates, you can incrementally update the Merkle tree rather than rebuilding it from scratch every time a change occurs.
Leaf Node Updates:
Inserts: When a new data block is inserted, a new leaf node is created. You only need to calculate the hash for this new data block and update the parent nodes up to the root.
Updates: When an existing data block is updated, the hash of the corresponding leaf node is recalculated. Then, propagate this change upwards by recalculating the hashes of the parent nodes up to the root.
Partial Tree Recalculation:
Rather than recalculating the entire tree, only the branch affected by the change is recalculated. This reduces the amount of work required, as unaffected branches remain the same.
In a binary tree, an update only affects O(logn)O(\log n)O(logn) nodes, making this approach much more efficient than recalculating the entire tree.
Handling High Write Throughput
In scenarios with very high write throughput, where multiple inserts and updates occur simultaneously, you can use the following strategies:
Batching Writes:
Instead of updating the Merkle tree after every single write operation, you can batch multiple writes together and update the tree in a single operation. This reduces the number of times the tree needs to be updated, improving overall efficiency.
For example, you might update the tree every few seconds or after a certain number of write operations.
Asynchronous Updates:
You can decouple the write operations from the Merkle tree updates by handling the updates asynchronously. Write operations can be processed immediately, while the Merkle tree is updated in the background.
This can be done using a background worker or task queue that processes updates in batches.
Merkle Forests:
In extremely high write scenarios, you could employ a "Merkle forest" approach, where multiple smaller Merkle trees (each representing a subset of the data) are maintained instead of a single large tree. This allows for more localised updates and easier parallelisation.
When checking for data variance, you would compare the corresponding trees in the forest, which can be done in parallel, speeding up the process.
Consistency and Synchronisation
In distributed systems with high write loads, consistency and synchronisation between nodes become critical:
Eventual Consistency:
You can relax strict consistency requirements and use eventual consistency, where all nodes eventually converge to the same state. The Merkle tree updates may lag slightly behind the actual data writes but will catch up over time.
Optimistic Concurrency Control:
Implement optimistic concurrency control mechanisms where you assume writes will not conflict, and the Merkle tree updates are validated later. If a conflict is detected (e.g., two nodes attempt to update the same data block), you can resolve it by reconciling the Merkle trees and updating the affected branches.
Snapshotting:
Periodically take snapshots of the entire dataset and create a Merkle tree for each snapshot. This approach is useful for auditing and rollback purposes, allowing you to compare the state of the data store at different points in time.
Example: High Write Scenario
Imagine a scenario where you have a distributed database that experiences a high volume of inserts and updates per second:
Step 1: Batch Writes
The database batches incoming write operations and applies them in groups.
Step 2: Update Merkle Tree Incrementally
After each batch, the affected parts of the Merkle tree are updated incrementally. If a batch affects 10 different data blocks, only those branches of the tree are recalculated.
Step 3: Use Background Processing
A background task queue is used to handle Merkle tree updates asynchronously, ensuring that the write operations are not slowed down by the tree updates.
Step 4: Periodic Full Rebuilds
Depending on the system’s requirements, you might perform a full Merkle tree rebuild periodically (e.g., once a day) to ensure the tree accurately reflects the entire dataset.
Trade-offs
While these strategies help manage the computational load of maintaining a Merkle tree in a high-write scenario, there are trade-offs:
Consistency Lag: There may be a slight delay between the data being written and the Merkle tree reflecting that data, which could impact real-time consistency checks.
Complexity: Implementing asynchronous updates, batching, and optimistic concurrency control adds complexity to the system.
Resource Utilisation: Batching and background processing reduce the immediate load but increase memory and CPU usage due to deferred processing.
Conclusion
Handling a high write scenario with Merkle trees requires careful consideration of how to balance efficiency with consistency. By incrementally updating the tree, batching writes, and using asynchronous processing, you can maintain the benefits of using Merkle trees while scaling to handle large volumes of write operations. The key is to optimize the update process to minimize the overhead while still ensuring that the tree accurately reflects the state of the data store.